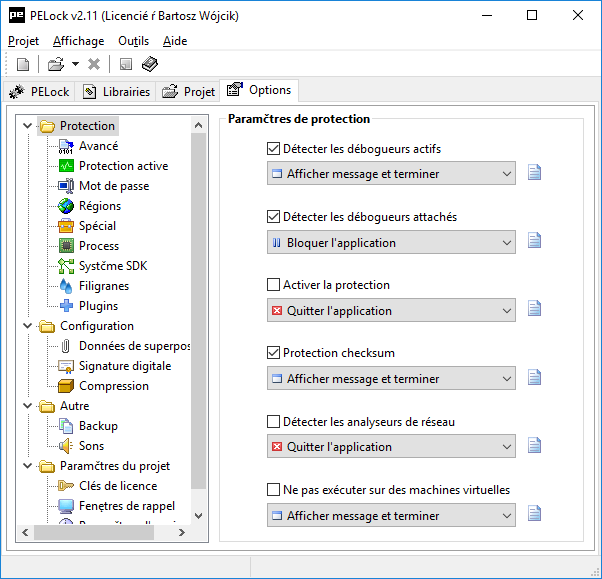
Kilka dni temu wydana została nowa wersja mojego oprogramowania PELock v2.0.
Zabezpieczenie oprogramowania przed złamaniem
PELock to system pozwalający zabezpieczyć dowolne 32 bitowe oprogramowanie dla systemu Windows przed złamaniem (ang. cracking), modyfikacjami oraz ochronić je przed inżynierią wsteczną (ang. reverse engineering).
System licencyjny
PELock posiada wbudowany system licencyjny, dzięki któremu możesz w prosty sposób dodać klucze licencyjne do swojego oprogramowania. Możliwe jest również ustawienie ograniczeń czasowych (ang. time-trial) np. 30 dniowy okres użytkowania dla zabezpieczonych aplikacji.
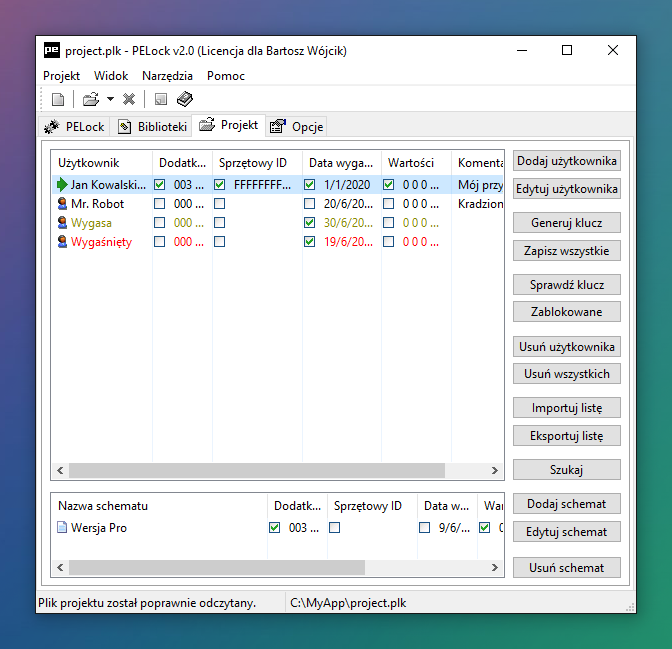
Możesz dodatkowo ściśle zintegrować zabezpieczenia i elementy systemu licencyjnego wykorzystując dedykowane SDK i setki przykładów użycia z pełnymi kodami źródłowymi dla C/C++, Delphi, Lazarus, Freepascal, PureBasic, PowerBASIC, D, Assembler.
PELock posiada wbudowany binder dla dodatkowych bibliotek DLL, dzięki któremu możliwe jest połączenie pliku aplikacji EXE oraz dodatkowych bibliotek DLL do jednego, wyjściowego pliku EXE.
Wirtualne biblioteki DLL
Zabezpieczyć możesz dowolny skompilowany program dla systemu Windows kompatybilny z formatem Portable Executable, niezależnie w jakim języku i środowisku programowania został stworzony.
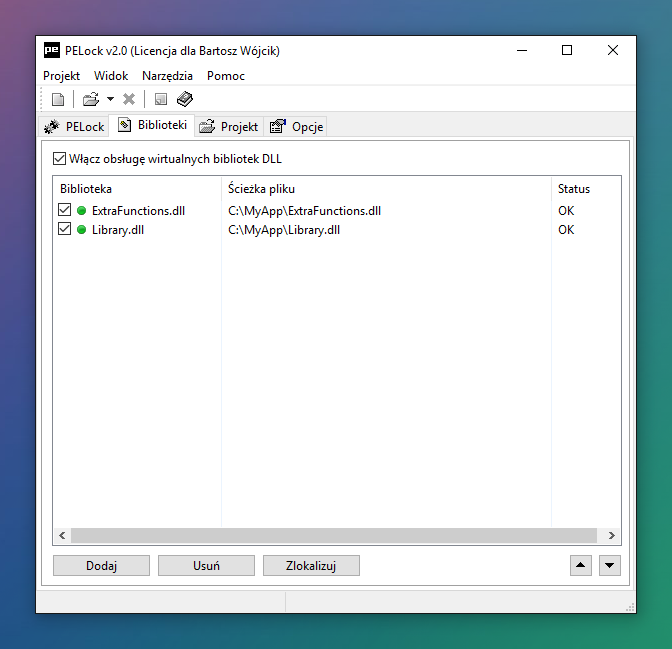
Jeśli twoja aplikacja wykorzystuje lub wymaga do działania dodatkowych bibliotek DLL możesz je ukryć wewnątrz zabezpieczonej aplikacji, nikt postronny nie będzie w stanie ich podejrzeć, ani żaden inny program nie będzie miał do nich dostępu, bo cały proces ich ładowania jest emulowany w pamięci i nic nie jest zapisywane na dysku, a działanie aplikacji pozostanie takie samo.
Linki
Strona domowa – https://www.pelock.com/pl/produkty/pelock
Zrzuty ekranu – https://www.pelock.com/pl/produkty/pelock/zrzuty
Pobieranie – https://www.pelock.com/pl/produkty/pelock/pobierz
Historia zmian
v2.0
Zabezpieczenia
- nowy silnik metamorficzny
- nowy wielowarstwowy silnik polimorficzny
- nowe wielowątkowe zabezpieczenie
- ochrona pliku aplikacji przed modyfikacjami
- emulacja standardowych funkcji WinApi
- generowanie białego szumu wywołaniami funkcji WinApi
- wgrywanie obrazu pliku pod losowy adres bazowy
- ochrona tabeli inicjalizacyjnej dla aplikacji Delphi
- zapobieganie uruchomieniu dwóch kopii tej samej aplikacji
- wykrywanie obecności wirtualnych maszyn
- aktywna ochrona z własną listą niepożądanych narzędzi
- dodatkowe opcje zapisu hasła chroniącego zaszyfrowany plik do Rejestru Windows
- możliwość wprowadzenia hasła z linii komend
- opcja pozwalająca wyłączyć szyfrowanie danych aplikacji wedle hasła
- ukrywanie klas obiektów COM
- wykrywanie programów śledzących interfejsy COM
- wykrywanie snifferów sieciowych
- ochrona entrypoint’a przed programami śledzącymi
- dodana wyszukiwarka makr, pozwalająca przeanalizować poprawność umieszczenia markerów SDK
- nowe makra
PELOCK_CHECKPOINT i PELOCK_CPUID
- funkcje inicjalizujące
PELOCK_INIT_CALLBACK
- makro ochrony pamięci
PELOCK_MEMORY_GAP
- chronione wartości liczbowe
PELOCK_DWORD
- wykrywanie stanu zabezpieczenia przez funkcje
IsPELockPresent
- funkcje szyfrujące dane
EncryptData / DecryptData
- funkcje szyfrujące pamięć procesu
EncryptMemory / DecryptMemory
- możliwość wyłączenia obsługi wybranych makr
- system znaków wodnych (watermarks)
- znaki wodne w formie makr
PELOCK_WATERMARK
- opcja uruchamiania aplikacji tylko w wybranych krajach
- przekazywanie domyślnych parametrów w linii komend
- zabezpieczanie aplikacji usług systemu Windows (tzw. services)
- możliwość wyłączenia ochrony DEP dla zabezpieczanych aplikacji
- opcja do sprawdzania praw administracyjnych
- możliwość wyłączenia wizualnych tematów do wyświetlania aplikacji
- dodana kompatybilność z hookami oprogramowania Kaspersky Anti-Virus
- pełna kompatybilność zabezpieczonych aplikacji z najnowszymi systemami Windows XP SP2 (32 bit), Windows XP (64 bit), Windows Vista (32/64 bit), Windows 7 (32/64 bit), Windows 8 (32/64 bit), Windows 8.1 (32/64 bit) i Windows 10 (32/64 bit)
System licencyjny
- NOWY SYSTEM LICENCYJNY
- funkcje API systemu licencyjnego obsługują oprócz ciągów ANSI, ciągi UNICODE
- zwiększony limit rozmiaru nazwy użytkownika do 8192 znaków (8 kB)
- możliwość zapisu kluczy licencyjnych w rejestrze Windows (dodatkowy format kluczy)
- kompresja plików kluczy licencyjnych do formatu ZIP
- funkcja do sprawdzania statusu klucza licencyjnego
- nowe opcje pozwalające stworzyć czasowo ograniczoną aplikację
- usuwanie lokalnych danych rejestracyjnych z Rejestru Windows
- dodatkowa funkcja API, pozwalająca wczytać klucz licencyjny z bufora pamięci
- odczytywanie z klucza licencyjnego 16 dowolnie ustawionych wartości liczbowych
- możliwość ustawienia nazwy użytkownika, poprzez przeciągnięcie pliku zawierającego informację o użytkowniku (dowolne rozszerzenie) na okno projektu
- usuwanie pustych znaków z końca nazwy użytkownika
- opcjonalne szyfrowanie wszystkich danych klucza według identyfikatora sprzętowego
- automatyczne sortowanie nazw użytkowników projektu (alfabetycznie)
- poprawiona obsługa wgrywania plików/projektów z linii komend
- opcja wyświetlania obrazków, wyświetlania komunikatów oraz otwierania stron internetowych na początku i na końcu działania zabezpieczonej aplikacji w przypadku braku danych licencyjnych
- możliwość wczytania listy użytkowników z innego pliku projektu lub zaimportowania z pliku CSV
- procedura pozwalająca wyłączyć klucz licencyjny
- możliwość przeładowania klucza licencyjnego z domyślnych lokalizacji
- możliwość ustawienia własnej procedury identyfikatora sprzętowego
- możliwość odczytu czasu wykorzystania klucza licencyjnego w bieżącej sesji programu
- większa kontrola nad makrami i wybranymi funkcjami systemu SDK
Generator kluczy
- całkowicie nowy generator kluczy
- generator kluczy cgi-bin dla systemu Linux
- przykłady w PHP jak generować klucze online
SDK
- nowe i udoskonalone przykłady dla C, C++, Delphi, Lazarus, PureBasic, PowerBasic, D, MASM
- obsługa kompilatorów MinGW / GCC dla Windows, Pelles C, PowerBASIC (uaktualnione pliki nagłówkowe)
- klasa
CPELock dla języka C++
- komponent
TPELock dla Delphi
- klasa
PELock dla języka D
Interfejs
- nowe okno opcji
- okno z globalnymi opcjami
- możliwość zmiany rozmiaru okna aplikacji
- możliwość zmiany języka aplikacji bez potrzeby ponownego uruchamiania programu
- dodana lista ostatnio używanych plików, wystarczy kliknąć przycisk oznaczony ◀, albo kliknąć prawym klawiszem myszy na belkę z nazwą pliku, aby otworzyć menu z listą ostatnio używanych plików
- automatyczne wypełnianie pola zawierającego sprzętowy identyfikator, gdy użytkownik zaznaczy tą opcję, a w schowku będzie znajdował się poprawny ciąg znaków identyfikatora, zostanie on automatycznie ustawiony w okienku edycyjnym identyfikatora sprzętowego
- uaktualniony dział FAQ (m.in. optymalizacja kompilatora i makra
DEMO w MS Visual C++ / Borland C++ / Delphi)
- usunięty problem z wyświetlaniem elementów, przy włączonych dużych fontach w systemie (120 DPI i wzwyż)
- usunięty problem z błędnie wyświetlanymi dymkami pomocy
- ikony zamiast przycisków „Edytuj”
- automatyczne uzupełnianie ścieżek plików, URL i katalogów w wybranych polach edycyjnych
- dodatkowe parametry linii komend
Kompresja
- domyślnie używany jest rodzaj kompresji typu solid w celu osiągnięcia lepszych rezultatów kompresji
- automatyczne testowanie wszystkich algorytmów kompresji w celu wybrania najlepszego
- możliwość całkowitego wyłączenia kompresji danych aplikacji
- możliwość wyłączenia kompresji zasobów
- dodana możliwość wyboru rodzajów zasobów, które mają zostać poddane kompresji lub też nie
- dodane różne algorytmy kompresji, włączając QuickLZ, UCL, zlib, miniLZO, HLZ, BriefLZ, JCALG1 and Mini-LZ
- możliwość wykorzystania własnej biblioteki kompresji
- losowy dobór algorytmu kompresji
Inne
- generowanie plików wyjściowych przyjaznych oprogramowaniu antywirusowemu
- tworzenie plików wsadowych pozwalających odtworzyć zabezpieczony plik z kopii zapasowej
- zapisywanie plików zapasowych do wybranego katalogu
- cyfrowe podpisywanie zabezpieczonych aplikacji (wsparcie dla podwójnych podpisów)
- wsparcie dla plików wykorzystujących technolgie anty-exploitacyjne CFGuard oraz SAFESEH
- w pełni kompatybilna obsługa funkcji TLS Callbacks
- zachowywanie daty zabezpieczanego pliku
- zachowywanie atrybutów zabezpieczanego pliku
- zachowywanie oryginalnego identyfikatora strefy bezpieczeństwa
- powiadomienia dźwiękowe
- wykorzystanie zdalnego systemu licencyjnego do poprawnej pracy PELock’a
- wyświetlanie ekranu powitalnego podczas uruchamiania i zamykania zabezpieczonej aplikacji
- wykrywanie plików chronionych przez mechanizm Windows File Protection (WFP)
- opcja używaj mocy tylko jednego procesora
- ustawianie priorytetu zabezpieczanego procesu oraz samego loadera
- opcja opóźnij uruchomienie aplikacji
- zamykanie systemu Windows po zamknięciu zabezpieczonej aplikacji
- usunięte problemy z wyciekaniem pamięci (z ang. memory leaks)
- przepisany kod przywracający pliki z kopii zapasowej
- łączenie pustych sekcji w wynikowym pliku
- wypełnianie odstępów między sekcjami przypadkowymi bajtami
- wyrównywanie rozmiaru loadera do wartości file align
- opcja pozwalająca na usuwanie struktury eksportowanych funkcji
- statyczne ładowanie bibliotek aplikacji
- nazwa opcji „Usuwaj dodatkowe dane z końca pliku” zamieniona na „Zachowaj dodatkowe dane z końca pliku”, dodatkowo zawiera nowe opcje, pozwalające określić w jaki sposób mają być obsługiwane nadmiarowe dane (emulacja)
- możliwość dodania na koniec zabezpieczonej aplikacji własnego pliku
- możliwość rozszerzenia rozmiaru pliku do dowolnej wielkości
- obsługa aplikacji ze ścieżkami UNC (mechanizm WebDAV) do bibliotek dynamicznych DLL w tabeli importów
- obsługa plików konfiguracyjnych i projektów większych niz 64 kB niezależnie od systemu operacyjnego