Jeśli myślisz, że jesteś zajebistym reverserem, bo przez ostatnie 20 lat przeanalizowałeś 500 rootkitów, 3000 dropperów, zbudowałeś mikroskop elektronowy w garażu i wygrałeś większość konkursów CTF – siądź wygodnie bo być może dostaniesz zawału jak przeczytasz tego jakby nie patrzył starego już bloga i tematy na nim poruszone
Moja reakcja jak zobaczyłem to wszystko, przejrzałem kod i techniczne aspekty:
A co tam piszą, że tak się podniecam?
mutacja formatu PE z obsługą przenoszenia funkcji, obfuskacją kodu, naprawianiem wszystkich struktur, obsługą wszystkich możliwych problemów technicznych
głęboka analiza maszyny wirtualnej w VMProtect 2 i 3, assembler dla VMProtect jakbyś chciał sobie popisać w low-levelu VMProtecta
eksploitacja anti-cheatów w celu iniekcji kodu do innych procesów
budowanie silników metamorficznych
budowa obfuskatora dla LLVM
…i jeszcze tona innych tak zaawansowanych tematów, których nie widziałem jeszcze nigdy u nikogo poruszonych.
Osoby stojące za tym są w fazie wydawania unpackera dla najnowszych wersji VMProtect i budują nowy rodzaj zabezpieczenia dla plików PE32/64, ale nie wiecie tego ode mnie jakby co.
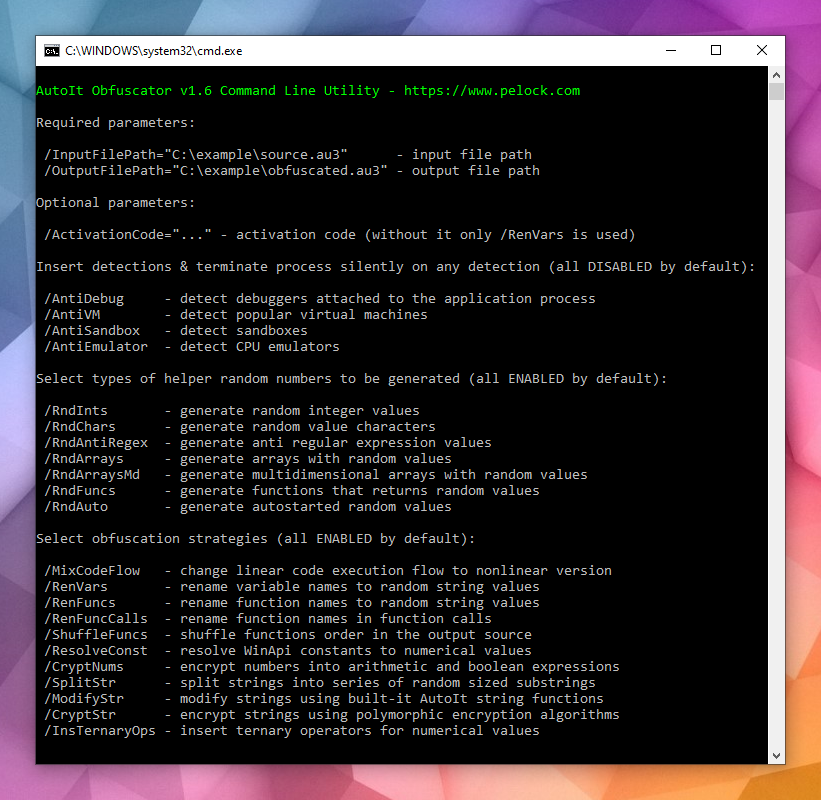
Wydałem kilka dni temu ulepszoną wersję mojego obufscatora dla języka autoit, czyli AutoIt Obfuscator. Dodane zostało wstrzykiwanie kodu do detekcji wielu narzędzi służących do reversingu i analizy zabezpieczonych skryptów.
Wstrzykiwany kod jest automatycznie wykonywany zaraz na początku działania skryptów i w razie pozytywnej detekcji jakiegokolwiek narzędzia – cicho kończy działanie skryptu, bez żadnego komunikatu o błędzie.
Dodane detekcje to m.in.
Antydebugging
Wykrywanie debuggerów dołączonych do do procesu aplikacji
Sprawdzaj podejrzanie małą liczbę rdzeni procesora (wyjdź jeśli jest ich mniej niż 3)
Sandboxie (biblioteki DLL)
Joe Sandbox (procesy)
Wykrywanie emulatorów CPU
WINE (niekonsystencje w funkcjach API, biblioteki DLL, specjalne funkcje API)
Bochs (WMI BIOS)
QEMU (procesy, WMI BIOS)
XEN (procesy)
Trochę mi zajęło skompletowanie tych metod, dlatego są one dostępne jedynie w płatnej wersji obfuscatora, ale wiem, że was na to stać i możecie sobie to przetestować online na
PS. Pozdrawiam Fabka za podsunięcie metod detekcji i w sumie naprowadzenie mnie na możliwość dołączenia tej funkcjonalności do mojego obfuscatora.
PS2. Jeśli znacie jakieś fajne metody detekcji, dopiszcie do komentarzy kod albo linki, ograniczeniem AutoIt jest w teorii brak dostępu do PEB czy TEB legitnymi metodami, więc interesują mnie jedynie rozwiązania oparte o legitne sposoby przez WinAPI i pokrewne funkcje.
Jak donosi DailyDarkWeb rzekomo wykradziono bazę danych serwisu LinkedIn z 2023 roku z 2.5 milionami rekordów. Jeśli to prawda, to będzie oznaczało, że LinkedIn postanowiło kontynuować bogatą tradycję, w której co ileś lat wykradane są miliony danych profilowych z ich serwisu.
Zgłosił się do mnie klient z projektem, którego celem było dojście do tego, czy w danym obrazku nie znajdują się ukryte informacje zakodowane poprzez steganografię.
Poniżej prezentuję skrypt w Pythonie, który wyciąga piksele w trybach horyzontalnych (czyli piksel po pikselu na wysokość obrazka) i wertykalnych z grafiki:
najmniej znaczące bity w składowych R
najmniej znaczące bity w składowych G
najmniej znaczące bity w składowych B
najmniej znaczące bity w składowych ALPHA
kombinowane najmniej znaczące bity w RGB
kombinowane najmniej znaczące bity w BGR
kombinowane najmniej znaczące bity w RGBA
kombinowane najmniej znaczące bity w ABGR
Są to najczęściej stosowane metody używane przez narzędzia do steganografii do ukrywania rozbitych danych w najmniej znaczących bitach składowych kolorów RGB.